
Data-Driven Business Models

Reserach Question:“What types of business model are present among companies relying on data as a resource of major importance for their business (key resource)?”
Objectives
The exponential growth of available and potentially valuable data compounded by the Internet, social media, cloud computing and mobile devices – often refered to as big data, has an embedded value potential that must be commercialised. Correspondingly, the quote ‘Data is the new oil’ became widespread and established the analogy to natural resources needing to be exploited and refined to guarantee growth and profit. The existing literature highlights a general gap concerning ‘if’ and ‘how’ big data actually creates value for companies. Notably, scholars have published surprisingly little on this topic. Most of the studies are commissioned by consultancies and IT vendors. Hence, understanding what business models relying on data look like remains a research question. Therefore, the purpose of this research is to propose a taxonomy of business models used by firms that rely on data as a resource of major importance for their business – aka data- driven business models (DDBMs).
During 2013, the research has received some funds from EPSRC NEMODE to focus on capturing value from Big Data through data driven business models; patterns from the start-up world (100 companies). In 2014, the research will extend this study by incorporating bigger sample of start-ups (2000 companies) to validate and test the proposed taxonomy. From another perspective, established companies incidentally creating and collecting data via their core business may as well lead to further types of business models. Therefore, we will test the DDBM framework and analyse established organisations use the data as a key resource for their business model.
More specifically:
- What does a framework look like that allows systematic analysis and comparison of data-driven business models?
- What clusters of companies with similar business models exist?
Approach
In 2013, a framework of dimensions and features, which are particularly insightful when assessing data-driven business models, is derived from existing business model research. This framework is used to code a sample of over three hundred publicly available documents describing the business models of 100 start-ups taken from a leading portal for business angels and venture capitalists. Established clustering algorithms applied to the results of the coding process lead to six DDBM types characterised by distinct combinations of dimensions and features from the proposed framework. In a series of interviews with start-up representatives from the sampling the patterns are confirmed by comparing the algorithmically identified clusters with the competitive landscape sketched by the interviewees.
The main focus in 2014 is to test and validate the DDBM taxonomy by using a larger sample of 2000 companies. EC-HVEN international research staff scheme will fund a research visitor to conduct this research. The study will use the ‘design science research’ (DSR) approach, which is part of the data analytical techniques and orientation used to conduct research into information systems (IS). The artefact will essentially propose an appropriate solution with five main layers. Data collection layer aims to automatically crawling data from a leading portal for business angels, venture capitalists and other relevant secondary resources. Data processing layer will use statistical techniques to automatically remove redundancy, cleaning data and estimate missing value. DDBM framework will be used to analyse the 2000 and store them in one database. The data storage layer will be used as a knowledge base for queries and data mining analyses. Data mining layer will use different clustering algorithms such as K-medoid, Markov model and Naïve Bayes to analyse the 2000 companies and generate the DDBM taxonomy. Visualization layer will involve the analysis reports and statistical graphs as result of the analysis.
Outputs
The outcome of 2013 research is six different clusters (Types A–F) were identified, as shown in figure 1, characterised by their respective cluster medoids. The taxonomy derived from our research consists of six different types of start-up DDBM. The proposed taxonomy will help companies to position their activities in the current landscape. However, the study was limited to 100 start-up companies, which did not allow testing of the study’s findings for external validity by using a split sample. Therefore, the 2014 outcome will produce more comprehensive DDBM taxonomy based on tested sample (2000 companies).
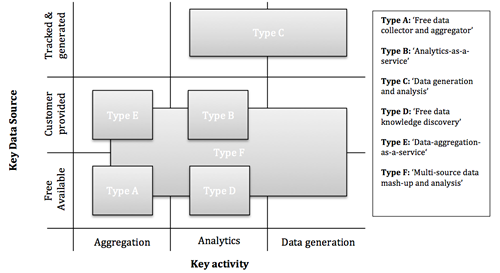
Figure 1 DDBM matrix of centroids
Researchers
Mohamed Zaki